Come Google indicizza i PDF: conclusioni finali
Il 26 di ottobre scorso ho “rilasciato” in rete un test per capire come i motori di ricerca indicizzano i documenti PDF. Il test aveva come scopo quello di capire le seguenti cose:
- Se gli stile headers (che normalmente vengono utilizzati per creare documenti professionalmente validi) di Microsoft word (nel mio caso, ma poco avrebbe fatto differenza se lo stile fosse stato generato da un altro editor) avessero un impatto nelle funzioni di indicizzazione.
- Valutare in che percentuale la Keyword density del documento pesasse in questa operazione
- Valutare l’impatto delle proprietà del documento (Titolo, Soggetto, Commento e Keywords)
Dopo una settimana esatta Google (per gli altri motori lo sapremo solo quando si degneranno di indicizzare i documenti in questione) mi ha restituito I primi risultati, che potete vedere in queste immagini qui sotto che presento in formato doppio. Lo scopo e’ quello di evidenziare delle fluttuazioni tra un giorno e l’altro.
Questi sono I primi due – piu’ interessanti - risultati che ho notato durante le passate settimane per il documento principale restituito dalla SERP generata usando la URK “seiunamicone”.
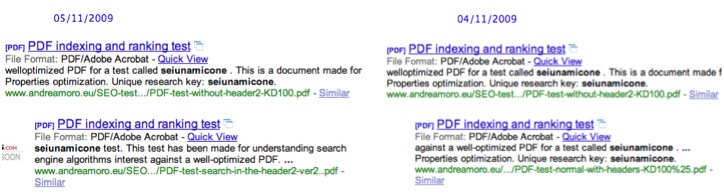 A seguire, i risultati che si ottengono espandendo l’apposito menu.
A seguire, i risultati che si ottengono espandendo l’apposito menu.
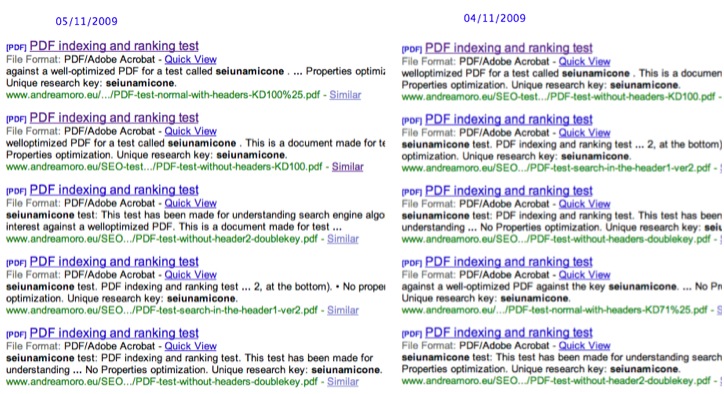 Sto monitorando la SERP da diversi giorni (settimane) e dopo una fase iniziale di puro assestamento, i risultati sembrano ora essersi stabilizzati.
Sto monitorando la SERP da diversi giorni (settimane) e dopo una fase iniziale di puro assestamento, i risultati sembrano ora essersi stabilizzati.
Mostrare una valanga d’immagini forse sarebbe stato troppo confusionario, ma vi posso assicurare che vi sono state altre fluttuazioni rispetto a quelle ora mostrate, e con molta probabilità, se controllerò già domani, ve ne saranno ancora.
Ad esempio il 03/11/2009 il terzo risultato era il documento denominato PDF-test-without-headers-KD43.pdf – il mio test n. 11. Se devo essere onesto il vederlo li portava ogni mio ragionamento fuori da tutte le possibili logiche.
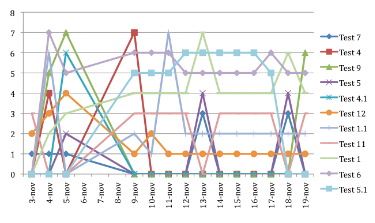
Per questa ragione ho deciso di includere due grafici che sono piuttosto esplicativi.
Il primo con tutti i risultati, anche quelli non pertinenti.
Il secondo con soli I risultati che realmente hanno mostrato qualcosa in termini di dati da analizzare.
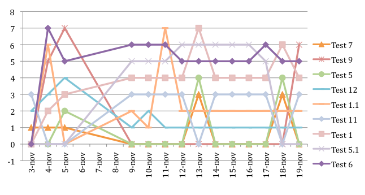
Analizziamo assieme I risultati, ma prima un breve ripasso su quali sono stati I parametric con I quali I documenti sono stati generati. Ho fissato come chiave di ricerca unica la parola “seiunamicone”, divendo la stessa con una densita’ del 100% nel documento di cui 42% nelle proprieta’ del documento e il restante 56% tra gli header (veri e/o fasulli).
Il primo documento ad essere stato indicizzato è stato il Test 7 (PDF-test-without-header2-KD100.pdf), ovvero un documento con H1 generato con gli stili, un H2 fasullo – pura enfatizzazione - una KD del 100% di cui 42% nella pagina e il restante 58% nelle proprietà del pdf. Il documento, dopo qualche giorno di gloria, è stato spazzato via dalla SERP, per fare capolino di tanto in tanto. Stessa sorte è toccata al Test 5, mentre non sono stati indicizzati per nulla i test 3, 10 e 13 per esempio.
Se vogliamo analizzare i primi tre risultati (Il primo e il suo aggregato, più il primo risultato che si ottiene espandendo gli elementi nascosti) otteniamo dei risultati interessanti.
Ma cosa ha fatto la differenza per questi documenti?
Posso affermare - quasi con certezza - che Google interpreta correttamente la codifica RTF del documento originale (non so’ come faccia esattamente, probabilmente come fanno tutti quei software in grado di restituire un documento editabile da un PDF).
Infatti, analizzando la SERP, dietro al fattore KD, si può notare come gli headers inseriti abbiano giocato il loro fattore chiave.
Questo è importante perché l’uso di un Header, piuttosto che di una enfatizzazione viene considerato in maniera differente e questo risponde ad una parte del quesito che mi ero posto quando avevo iniziato il test.
Quanto agli altri quesiti che mi ero posto, si può affermare che per ottimizzare un PDF per i motori di ricerca, i seguenti fattori risultato essere quelli coinvolti:
- Utilizzo delle proprietà del documento. Ricordiamoci di inserire la parola chiave di nostro interesse nelle proprietà principali (Title, Subject e Keywords – Commenti viene ignorata)
- Utilizzo di un header 1. Inserire la parola chiave di nostro interesse nell’header 1 (fatto con lo stile quindi, e non solo enfatizzando il testo) per favorire il posizionamento. Mettere un header 2 ha valore, ma durante i test ho notato che metterli entrambe non offre maggiori possibilità che metterne solo uno.
- Keyword density. Un numero adeguato di parole chiave nei punti critici è - come per le pagine HTML – un determinato peso che aumenta di valore qualora le parole vengono usate congiuntamente con gli headers. Tuttavia vanno sempre considerati dei fattori importanti quali la lunghezza e il peso del documento, i quali oltre una certa soglia non vengono indicizzati.
- Keyword proximity. Laddove non sono utilizzati gli headers, la prossimità delle parole chiave rispetto al documento gioca un fattore chiave.
Credo di non essermi dimenticato nulla e spero che questo test sia stato di tuo interesse.